![]() The open source SI4T (Search Integration for Tridion) project allows you to pass through 3 levels of control over what content gets indexed: Firstly, the default, zero-configuration behaviour. Then there is fine-grained configuration via metadata and parameters, and finally total extensibility by coding your own indexing TBBs. This article talks through how you can refine your indexing strategy by passing through these levels.
The open source SI4T (Search Integration for Tridion) project allows you to pass through 3 levels of control over what content gets indexed: Firstly, the default, zero-configuration behaviour. Then there is fine-grained configuration via metadata and parameters, and finally total extensibility by coding your own indexing TBBs. This article talks through how you can refine your indexing strategy by passing through these levels.
Overview: How does SI4T work?
First a quick overview of how SI4T works. The idea is that when you publish content, at the same time as deploying it in the normal way (files, binaries and metadata to file system and/or broker database), you push some data into a search engine index. This is done by using TBBs to generate a snippet of XML containing the indexing data and add it to the rendered item (Page or DCP)Â output. A storage extension then removes this at deployment time, and sends it to the search engine for indexing via a pluggable Indexer (the idea is to have different Indexers for different search engines, currently there is one for Solr, with others in development). The advantage of this “Push” type of indexing over, for example crawling is that your content is instantly indexed, and you have very fine control over what actually gets indexed, and into what index fields.
Basic setup – Out of the box behaviour
So how to get started? The good thing about SI4T templating is that it works with zero configuration – you just need to upload the SI4T Indexing template building blocks, drag and drop them in to your page template(s) using the Template Builder and you are ready to go. This is the most simple strategy – any page using a page template containing these TBBs will generate indexing data which will be added to the search index when the page is published.
So what exactly gets indexed? Check the package in the Template Builder and you will see some XML.

There are a bunch of standard fields like URL, page id and publication id, plus a catch-all body field which contains a concatenation of all text fields for all component presentations on the page, plus any in page metadata.
Next level – Configure
Excluding content
It is likely,however that you do not want every page, component presentation and/or field to be indexed – so you need to move to the next level of your indexing strategy. You can prevent individual pages from being indexed (for example it does not make sense to index your search results page itself) by adding a NoIndex page metadata field with value Yes. If certain Component Presentations on the page should not be indexed, put a similar NoIndex metadata value on the Component Template.
If you want to exclude a certain field, then add a SearchIndexManagedFields metadata value on the Template Building Block, or your Component Template containing the XML name of the field. For multiple fields, make this value a comma-separated list. The SI4T project contains an example metadata schema for templates and parameter schema for TBBs which contain these and other parameters.
You can also turn the logic on its head, and exclude all fields by default except those listed in the SearchIndexManagedFields parameter/metadata field. This is done by using a SearchIndexInclude parameter/metadata field with a value containing the token [exclude].
Custom field mapping
Next you may have particular fields in your index that you want to be searchable using some advanced searching on top of or instead of your free-text search. This is possible by specifying a SearchIndexCustomFieldMap Component Template Meta or TBB Parameter field containing a mapping string in the following format: indexField:contentField . Here any component or metadata fields with XML Name contentField will be added to a custom field called indexField. Custom fields appear in the custom element in the index XML.
If the index field has the same name as the content field, I can simply add the field name without the colon (eg contentField).
If I want to map several fields to the same custom field, I separate them with a comma (eg: date:eventDate,newsDate,startDate – will map differently named date fields from different schemas to the same date index field).
If a field is multi-value and/or I want to create multiple custom index field entries, I denote this with a +. For example the mapping location+:country,city will put both country and city content fields as separate values into the location index field. if either country or city is multi-value then separate values will be created for them too. Note that if you do not specify an index field as multi value, and multiple field values are mapped to it, then only the first one will be used in the index data. For example if we use the mapping location:country,city and country is multi-value, only the first country value will be indexed. If there is only one country, but also a city, then the first field which is found will be indexed.
If I want to map certain fields to the standard title element, I can do this by specifying a mapping for the special title field. For example the mapping title:headline,productTitle will look for a headline or productTitle field and put it in the title (if this mapping is not configured, or none is found the Page title is used by default).
Finally if I want to specify several mappings, I can delimit them in the same mapping string using pipes, for example:
summary|title:heading|date:newsDate,eventDate|location+:city,country
is a combination of all the above cases.
In the example below, I have decided to exclude all fields except the content field, and I am creating custom index fields for the summary and latitude fields, plus mapping the heading field to the title:
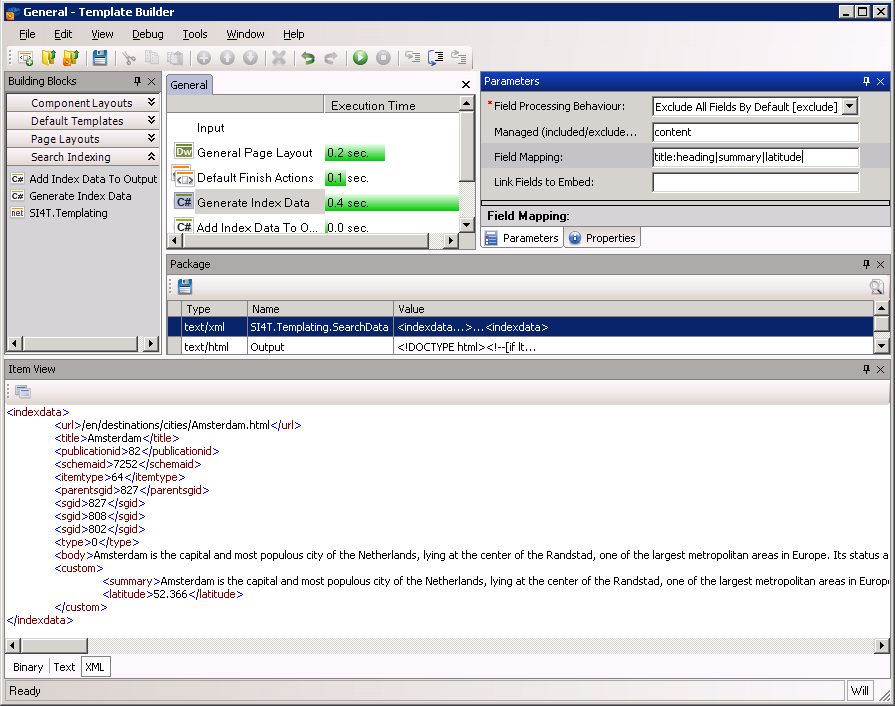
LINKED CONTENT
Most content models feature linked content, which often belongs the component that links to it (and is thus rendered as part of the page containing the main component). If you wish to also index this linked content, you need to specify the which component link fields to “embed” content from by using a SearchIndexLinkFieldsToEmbed metadata/parameter field value. This can contain a comma separated list of field names.
Not enough? Extend with your own logic
The above options do not require you to write a single line of code to generate your indexing data with a fine-level of control, which is great and should serve you for 80% or more of requirements. There are, however always situations where you need more control – now we move to the last level of your indexing strategy. You probably have the idea by now of how you can do it – simply swap out the default Generate Index Data TBB and code your own – you can generate whatever XML you like. All the SI4T TBBs and helper classes are extensible, so I would recommend extending the functionality they provide rather than starting from scratch. Heres a simple example of a TBB which additionally indexes the metadata on the page’s Structure Group:
More information on SI4T Wiki…
Hopefully you now have a better idea of how you can use SI4T to generate whatever indexing data you require. For more information including instructions to setup and end-to-end SI4T solution, check the project Wiki.Â
Amazing post Will. Really gives full fledged information on Indexing methods. Thanks